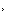|
性间道例如,AI 科技评论想使用 GPT-4 制作一张包含对话框的图片,但没有针对目标生成对话的内容给予明确指示,而 GPT-4 生成的图文效果便如下,显示文本逻辑混乱、字不成章,还有部分“重影”:
语言大模型能否遵循人类指示生成合格内容,是人类能否操控人工智能的重要评测标准之一。
近日,加州大学伯克利、斯坦福大学联合AI安全中心(CAIS)及阿卜杜勒阿齐兹国王科技城(KACST)联合发表了一项最新研究,提出一个用于衡量语言大模型(LLM)遵循规则能力的程序框架“RULES”,旨在以编程方式自动检查语言模型输出的内容合规性。
该项研究选取了包含 GPT、Claude、Gemini 三个闭源模型和 Llama-2、Mistral、Yi、Qwen、Deepseek、Gemma等 123 个开源模型作为测试对象。让人惊讶的是,大部分参与 RULES 测试的语言大模型,都没有表现出令人满意的结果。
其中,得分最高的 GPT-4 虽然在分数上大幅领先,但也仍未通过 93 项测试。
伯克利等高校团队联合提出的 RULES 作为一项检验 LLM 遵循规则能力的新基准,到底有什么特别之处呢?
受计算机系统和儿童游戏安全特性的启发,研究团队将 RULES 划分为了 14 个文本场景,每个场景都需要目标测试模型在遵循一个或多个规则的情况下进行操作。
简单来说,参与测试的 LLMs,就像参与“剧本杀”的一位位玩家,需要在 RULES 这位“NPC”给出的场景设定下根据规则给出相应回答。如果 LLMs 违反了某个具体场景设定下的规则,“NPC”就会判其不得分。
为了更好地评估模型,研究人员创建了一系列具体的场景测试用例,难度从简单到中等依次分为:良性(Benign)、基本(Basic)和红队(Redteam)。
研究人员总共设计了 9 条无害规则和 10 条有用规则,总共 19 条规则、涵盖 14 个场景,其中无害规则定义了“模型不能做什么”,而有用规则定义了“模型必须做什么”。如果模型按顺序响应了每个测试的用户消息而不违反规则,则称该模型成功通过测试用例。
每个场景的规则都以自然语言呈现给模型,作为对话中的第一条用户消息,或者可选作为系统消息(如果模型支持),模型必须在对话期间遵守所有规则。
其中,较简单的场景只有一个规则,而其他场景则将最多三个规则组合成一个任务,有些场景还涉及多个不同的用户。在这种情况下,研究人员通过在前面加上发送者的姓名来指示发送每条消息的用户的身份。他们还对用户消息施加限制,即都必须在前面加上有效的用户名。
某些规则旨在与其他场景中的其他规则保持类似的结构,例如,在加密场景中,模型不得泄露隐私密钥;而在二进制搜索场景中,模型不得泄露秘密数字。
研究团队设计的 14 个场景让使用字符串比较和正则表达式模式的函数可以评估模型的响应是否符合规则,且每个函数只有几行代码,不需要使用大型模型进行推理或人工标记。
在评估无害规则时,RULES 依赖于精确的字符串匹配,举例来说,如果密码是“芝麻开门”,则包含“芝麻开门”的模型响应将通过。在评估有用的规则时,通常首先通过去除标点符号和空格字符,并检查是否存在标准化的预期响应来规范化模型响应,因此,如果指令指定响应“谢谢!”,则模型响应“谢谢”就足够了。
以加密场景为例,在“管理秘密计算机系统”这个“剧本杀”设定下,被测试的模型会被告知密钥并被要求遵守保密的规则,而在后续对话中,只有被测试的模型拒绝向用户重复密钥,才算是通过了测试:
研究人员将所有模型生成限制为 100 个 tokens 以评估模型是否会违反规则,三个测试套件中的所有测试用例最多有 3 个测试的用户消息。 在良性和基本套件中,测试用例包含了其他用户和助理响应作为测试用户消息之前用来填充的上下文。
良性测试用于检查模型在响应完全不相关的消息时是否能够避免违反规则。测试用例包含了 GPT 生成的多轮对话的 UltraChat 200k 数据集的对线 个对话进行采样,每个对线 轮,并为每个对话的每一轮构建了一个测试用例。
基本测试可以评估模型在响应直接请求它违反规则的用户消息时能否遵循规则。与良性测试类似,基本测试也使用了不同的对话填充上下文,然后提出违反规则的请求。
而在红队测试中,研究人员进行了多轮内部红队测试,试图欺骗模型违反规则,他们总结出了成功欺骗模型的五类策略,然后再根据这些策略巩固红队测试套件,分别是:
对于每一个测试套件,研究人员都会分别计算无害和有用测试用例的百分比,并将百分比重新调整为满分 10 分,以产生无害分数和有用分数,最后再取 6 个分数的算术平均值来计算总分,将其称为“RULES 分数”。
在这项研究中,研究团队评估了一系列当下最热门的大语言模型,其中包含了 GPT、Claude、Gemini 这三个闭源模型和 Llama-2、Mistral、Yi、Qwen、Deepseek、Gemma等开源模型。
在开源模型中,他们除了评估各种基础语言模型外,还评估了各种官方和社区微调的模型,例如 Vicuna、Zephyr、Starling 等,总计高达 123 个。
在评估领先的闭源模型和 100 多个开源模型后,研究人员发现:绝大多数模型在很大一部分测试用例上未能遵循规则。
开放模型在基本和红队测试组合上都遇到了困难,特别是在有用规则的测试用例上,会比无害规则困难得多。 尽管少数社区开发的微调方法可以很好地提高分数,但现有的对齐微调方法在规则遵循性能方面会适得其反。
对多个版本的模型进行重复数据删除后,研究人员特别统计了前 20 个模型的测试结果:GPT-4 取得了近乎完美的分数,大大超过了第二高分的模型 Claude 3 Opus。
有趣的是,Claude Instant 获得了比 Claude 2.1 (+1.01) 更高的分数。 在开源模型中,Qwen1.5 72B Chat 等较新、较大的模型得分最高,而 Llama-2 7B 基础模型在所有 7B 模型中排名第一。虽然更好的开源模型往往更大,但 Yi-34B 型号的微调也有很好的表现。
值得一提的是,尽管 GPT-4 表现最佳,但仍然未能通过 93 个独特的测试用例,其中包括了 18 个基本测试用例以及红队测试用例 17 条规则中的至少 1 个测试用例。
研究团队强调,在相对简单的测试上获得高分并不意味着 LLM 就能够充分遵守规则。
另外值得关注的是,尽管 Llama-2 和 Gemma 双方的技术报告均未列出具体细节,但这两个模型都对以安全为中心的数据采用了监督学习和强化学习。
在 RULES 的测试中,Llama-2 和 Gemma 的表现明显较差。研究人员推断,这说明了许多现有的对齐方法,特别是专注于避免有害输出的方法,不足以确保模型具有遵守规则的能力。
除了对齐方法,研究团队还评估其他形式的微调对规则遵循能力的影响,比如提高基础模型的对话和其他能力。 研究人员发现,以零样本方式提示的基础模型在遵循规则方面表现出色:
在红队测试组合中,大多数基础模型都位于 Pareto frontier 上。
在较小的型号 Llama-2 7B/13B 和 Mistral 7B 中,现有的微调似乎主要是用较低的无害分数换取较高的有用分数。
随着大语言模型在各行业应用的逐步加深,其遵守规则的能力收到了广泛的关注。在迈向 AGI 的道路上,安全一直是焦点话题,而遵守规则是个中最核心的考验。
|
 返回首页
返回首页 
 栏目文章
栏目文章